

Wichtig ist zum einen um die Problemdefinition: Was genau soll mit Machine Learning getan werden? Je detaillierter der Use Case beschrieben ist, desto bessere Ergebnisse erhält der Anwender. Zum anderen ist die schiere Menge an Daten nicht alles; vielmehr spielen die Aussagekraft über den gewählten Use Case und die Qualität eine entscheidende Rolle. Zur Datenqualität gehören Indikatoren wie der Umfang an fehlenden Werten, die Synchronisation verschiedener Datenquellen sowie die Genauigkeit von Zeitstempeln.
In der Praxis stehen Daten oft in unterschiedlichen Formaten zur Verfügung. Sie müssen vorverarbeitet werden, um sie einem Machine-Learning-Algorithmus verständlich zu machen. Machine Learning ist folglich immer nur so gut wie die Daten, die während der Lernphase genutzt wurden. Ferner fehlt dem Modell ein tieferes Verständnis der Daten und des Use Cases. Ob seine Aussagen deshalb sinnvoll und zuverlässig sind, muss vom Menschen gründlich evaluiert werden, bevor das gelernte Modell in die produktive Anwendung geht.
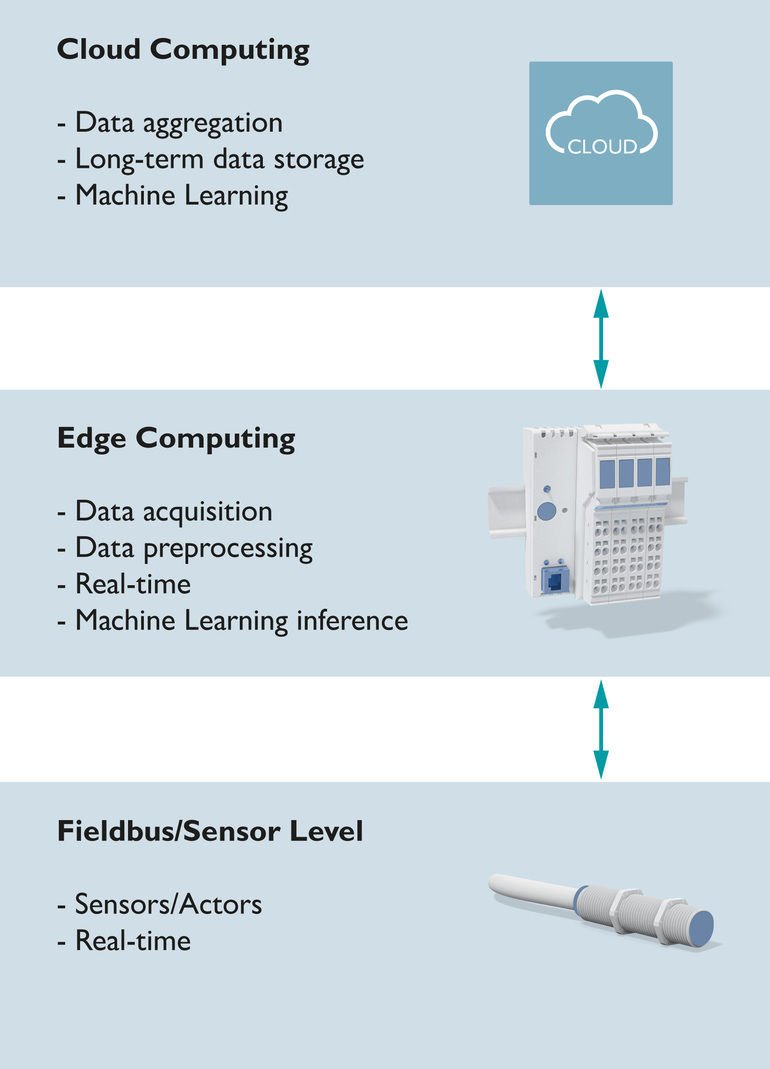
Stärken von Edge Computing und Cloud kombinieren
Abgesehen von der Auswahl der Daten und den verwendeten Modellen ergeben sich je nach Use Case verschiedene Anforderungen, wie und wo Machine Learning am besten eingesetzt wird. Hier stellt sich schnell die Frage, ob sich Cloud Computing oder Edge Computing als die optimale Herangehensweise erweist. Meist ist es sinnvoll, die Stärken beider Ansätze zu nutzen. Über die Cloud lassen sich die Daten von weltweit verteilten Feldgeräten erfassen sowie langfristig abspeichern. Für das Lernen von Modellen werden große Datenmengen und viel Rechenleistung benötigt. Die Cloud kann die erforderlichen Ressourcen sowie eine breite Datenbasis bereitstellen.
Nach dem Lernen folgt der Einsatz des Machine Learning Modells. Dies kann zwar in der Cloud geschehen, doch je nach Anforderung ist das Edge Computing ebenfalls als vorteilhaft. Im Vergleich zum Lernen bedingt die Verwendung des Modells „on the edge“ nur wenig Rechenleistung. Daher kann das Modell ebenso in auf der Feldebene installierten Geräten genutzt werden. Weil der Kommunikationsweg wegfällt, lassen sich schnelle Reaktionszeiten realisieren, die mit der Cloud nicht erreichbar sind. Mit Edge Computing ist es außerdem möglich, die Daten bereits im Gerät vorzuverarbeiten und lediglich Ergebnisse in die Cloud zu übertragen. So reduziert sich die Datenmenge, die in die Cloud geschickt wird.
Zunächst ein Modell des normalen Verhaltens lernen
Um Use Cases erfolgreich umzusetzen, ist ein iterativer Ansatz häufig der beste Weg. Im Data Science-Bereich gibt es einige Prozessmodelle, wie den Cross-Industry Standard Process for Data Mining und dessen Erweiterung Analytics Solutions Unified Method for Data Mining. Die beiden iterativen Prozessmodelle lassen sich gut mit agilen Entwicklungsmethoden – wie Scrum – kombinieren. So können die zu realisierenden Use Cases sukzessive verfeinert werden.
Das Beispiel einer Fehlererkennung verdeutlicht dies: Hierbei geht es um die frühzeitige Detektierung von bestimmten Fehlern respektive Fehlertypen. Für die Ausführung mit Machine Learning folgt daraus, dass alle spezifischen Fehler, die aufgedeckt werden sollen, in ausreichender Menge in den Trainingsdaten vorhanden sein müssen. Das bedingt, dass die Fehler in der Vergangenheit bereits aufgetreten und von Experten erkannt/beschriftet worden sind.
Zu Beginn des Projekts liegen solche Daten in der Regel nicht vor, da derartige Fehler im realen Betrieb der Anlage so gut wie nie vorkommen. Deshalb bietet es sich an, am Anfang etwas einfacher zu starten und zunächst ein Modell des normalen Verhaltens zu lernen. Dazu werden nur Daten aus dem regulären Betrieb – also ohne Fehler – benötigt. Das Modell wird dann trainiert, um Abweichungen vom Normalverhalten festzustellen. So werden zwar keine bestimmten Fehler detektiert, aber ein erster Mehrwert erzielt. Die aufgedeckten Anomalien lassen sich anschließend von Experten bewerten sowie als spezifische Fehler identifizieren und beschriften. Im Laufe der Zeit entsteht so eine Datenbasis für ein Modell, das die eingetretenen Fehler erkennt und eventuell vorhersagen kann.
Phoenix Contact GmbH & Co. KG


Zu den Autoren
Alexander von Birgelen und Arno Martin Fast sind beide Mitarbeiter im Bereich Cloud Engineering bei Phoenix Contact Electronics GmbH in Bad Pyrmont

Hier finden Sie mehr über:









{kind=link}