
Wo sind für den KI-Einsatz im Maschinenbau erfolgversprechende Segmente?
Sattler: Predictive Maintenance und Anomalieerkennung sind wichtige Bereiche, für die sich bereits KI-Lösungen im Einsatz befinden. Aber auch die Optimierung von Prozessen und der Prozesssteuerung, etwa durch Anpassung von Prozessparametern, bietet großes Potenzial.
Und wie geht man das an? Genügen große Datenmengen plus intelligente Algorithmen?
Sattler: Nein. Große Datenmengen allein genügen leider nicht. Zwar werden gerade für das Lernen mit tiefen Netzen große Trainingsdaten benötigt, aber dies erhöht natürlich auch den Aufwand der Datenerfassung, -vorbereitung und des Trainings. Daher kommt es darauf an, die richtigen Daten als Trainingsdaten zur Verfügung zu haben. So sollten die Trainingsdaten – beispielsweise für die Bilderkennung – natürlich die zu identifizierenden Objekte enthalten. Aber eben auch Negativbeispiele in allen möglichen Variationen.
Wie werden Daten zu brauchbaren Daten? Worauf kommt es beim Data Engineering an?
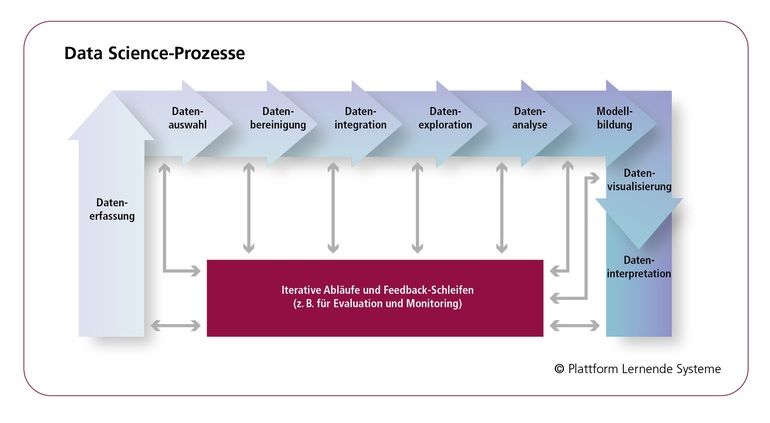
Sattler: Zunächst müssen überhaupt geeignete Daten erfasst werden, die das zu bearbeitende Problem repräsentieren. So sollten für eine Anwendung im Bereich Predictive Maintenance eben auch Fehlerzustände und nicht nur normale Betriebsdaten erfasst werden. Dann müssen die Daten aufbereitet werden. Dies umfasst die Bereinigung wie das Erkennen und Entfernen fehlerhafter Werte, die Verknüpfung mit anderen Daten und gegebenenfalls die Annotation der Daten. Der Aufwand dieser Vorbereitung kann in KI-Projekten bis zu 80 Prozent des Gesamtaufwands betragen.
Welche Fähigkeiten benötigen Entwickler, um sinnvolle KI-Anwendungen zu schaffen?
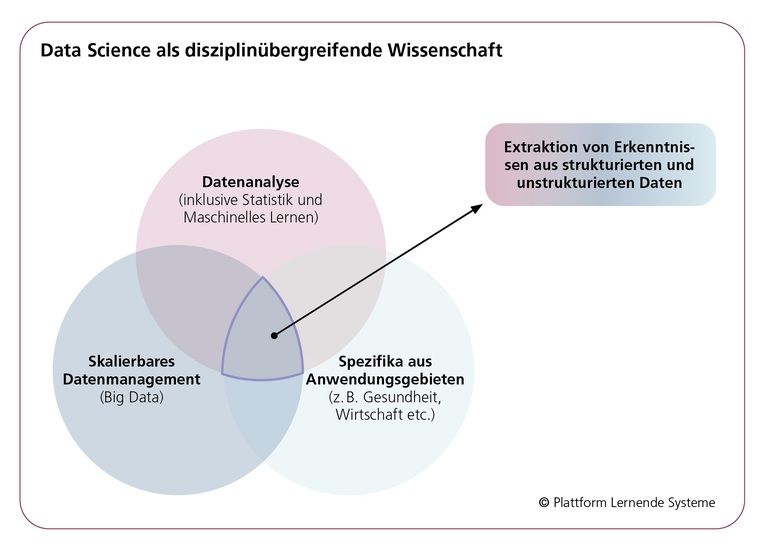
Sattler: Neben Methodenkenntnissen aus dem Bereich des maschinellen Lernens bzw. der Künstlichen Intelligenz sind dies insbesondere Kenntnisse zur Datenmodellierung, -transformation und -integration, aber auch Kenntnisse der Statistik, um Eigenschaften der Daten und die Qualität der Ergebnisse bewerten zu können. Ferner sind Kenntnisse aus den Bereichen Ethik und Recht hilfreich, um verantwortungsvoll mit den Daten umgehen zu können. Und natürlich ist auch umfassendes Anwendungswissen unabdingbar. Erforderlich ist also ein interdisziplinärer Zugang: Anwendungsexperten benötigen zunehmend Data-Literacy-Expertise und Data-Science-Fachleute müssen auch die Anwendungsdomänen verstehen. Hier wird sich sicher ein großer Bedarf an Weiterbildungsangeboten entwickeln.
Wie können solche Weiterbildungsangebote im Industrieumfeld aussehen? Braucht es Maschinenbauer mit Data Science? Oder einen Data Scientist mit Fachrichtung Maschinenbau?
Sattler: Es werden zunehmend Ingenieure benötigt, die datenzentrierte Methoden kennen, verstehen und anwenden können. Dies lässt sich durch geeignete Weiterbildungen kurzfristig erreichen, aber auch längerfristig durch entsprechende Studienmodule in klassischen Ingenieurstudiengängen. Daneben gibt es aber sicher auch Bedarf an Generalisten – also Datenwissenschaftlern, die sich in Anwendungsbereiche einarbeiten können, ähnlich wie das ja schon für Mathematiker, Physiker oder Informatiker gilt.
Kann man das Data Engineering und die Modellbildung auch einfacher gestalten beziehungsweise mit Tools so automatisieren, dass diese auch von Anwendungsexperten durchgeführt werden kann?
Sattler: Domänenexperten müssen keine ML-Experten sein, allerdings sollten sie ein Verständnis der Möglichkeiten und Grenzen der eingesetzten Methoden haben. Werkzeuge können hier sicher die Anwendbarkeit unterstützen, aber einen blinden Einsatz von ML-Tools und -Modellen halte ich nicht für ratsam. Gerade dort, wo Modelle erlernt werden, sollte klar sein, auf welchen Daten das Training basiert und welche Features bzw. Parameter verwendet wurden.
Wo liegen gerade in Maschinenbau und Industrie die besonderen Herausforderungen für eine Datenaufbereitung?
Sattler: Die Herausforderungen bestehen zum einen in der Heterogenität – etwa der Vielzahl von verschiedenen Sensoren und Daten-Austauschformaten – aber auch in der Qualität und Menge der Sensordaten. Datenaufbereitung und -bereinigung spielen hier eine wichtige Rolle, Echtzeitverarbeitung großer Datenmengen ebenfalls.
Stehen im Industrieumfeld denn überhaupt bereits alle notwendigen Daten der Maschinen und Komponenten etc. zur Verfügung?
Sattler: Das lässt sich so pauschal nicht beantworten und hängt vom jeweiligen Unternehmen und auch der Branche ab: viele moderne Anlagen sind schon vernetzt und bieten die Möglichkeit der Datenerfassung, in anderen Bereichen und Unternehmen steht die Digitalisierung noch an.
Was muss sich ändern, damit das Data Engineering im Maschinenbau einfacher wird?
Sattler: Der Zugang zu Prozessdaten muss vereinfacht werden, zum Beispiel durch Industrie- oder Branchenstandards. Anwenderfreundliche, robuste und domänenspezifische Werkzeuge zur Datenverarbeitung und -analyse werden benötigt, da sich die bei Datenwissenschaftlern beliebten Python-Notebooks nur bedingt für den rauen Industriebetrieb eignen. Und schließlich sollten Domänenexperten mit Data-Science-Kenntnis verfügbar sein.
Plattform Lernende Systeme
Acatech – Deutsche Akademie der Technikwissenschaften e.V.
www.plattform-lernende-systeme.de
Zur Person: Kai-Uwe Sattler
Der Informatiker Kai-Uwe Sattler ist Professor für Datenbanken und Informationssysteme an der TU Ilmenau. Er ist Mitglied der Arbeitsgruppe Technologische Wegbereiter und Data Science der Plattform Lernende Systeme und Co-Autor des Whitepapers „Von Daten zu KI“










{kind=link}